What Is a Data Lake?

By Manu Pradhan
Published on October 11, 2024

Organizations are generating and collecting massive amounts of data from various sources—internet, social media, IoT devices, business applications, and many more sources. To leverage the potential of this data, companies need solutions that can store, process, and analyze it efficiently and in some cases in real-time. This is where the concept of a data lake comes into play.
What is a data lake?
A data lake is a centralized repository that allows you to store all your structured, semi-structured, and unstructured data at any scale. This flexibility enables handling massive volumes of varied data types generated in modern enterprises.
Traditional data warehouses require data to be processed and structured before storage. By contrast, data lakes allow data to be stored in its raw form.
Key characteristics of a data lake
By understanding the key traits of a data lake, organizations can better utilize them effectively. Key characteristics of a data lake include:
Scalability: Data lakes can store and handle massive volumes of data, from gigabytes to petabytes, without sacrificing performance.
Flexibility: Data lakes ingest and store data from diverse sources, including logs, images, videos, and sensor data, alongside structured data like databases and spreadsheets.
Cost-effectiveness: Storing raw data in a data lake is often more cost-effective than using a data warehouse, as it eliminates the need for expensive preprocessing and transformation.
Data lake use cases
Advanced analytics: Data lakes can support a wide range of analytics, from simple queries to complex machine-learning models. They can also support big data processing, since data lakes can scale to store petabytes of data while enabling high-speed processing using distributed computing frameworks like Apache Spark and Hadoop, making them ideal for handling large-scale data initiatives.
IoT data management: The Internet of Things (IoT) generates massive volumes of continuous data streams. Data lakes can ingest, store, and process this influx of data from connected devices, helping businesses to track performance, monitor equipment, or analyze customer behavior in real-time.
Data archiving and compliance: With growing regulatory requirements, organizations need cost-efficient storage solutions for historical data. Data lakes serve as a long-term archive, ensuring that businesses retain data to meet compliance needs while providing an easy way to retrieve and analyze archived data when necessary.
Data science exploration and experimentation: Data lakes are highly flexible environments for data scientists to explore and experiment with different datasets. This flexibility allows them to prepare and test new models, perform data mining, or explore previously untapped datasets for innovative use cases.
Real-time data processing: Some industries, such as finance and telecommunications, require near-instantaneous data processing. Data lakes can integrate with streaming services like Apache Kafka to process real-time data, enabling timely insights for mission-critical applications like fraud detection or stock market predictions.
By offering scalable, cost-effective, and flexible storage, data lakes empower businesses to innovate across these diverse use cases, turning data into a strategic asset.
Benefits of using a data lake
Unifying Data Silos: Data lakes consolidate data silos by providing a single repository for all data types facilitating better decision-making.
Real-Time Analytics: Integrating with real-time data processing frameworks and analyzing streaming data as it’s ingested consequently results in providing timely insights and driving faster decision-making.
Accelerating Innovation: Organizations can leverage different data sets and analytics approaches, driving innovation.
Enhancing Business Agility: The flexibility and scalability of data lakes allow organizations to quickly adapt to changing business needs, whether it’s incorporating new data sources or scaling analytics capabilities.
Best practices of data lake management
While data lakes offer numerous advantages, without proper management, a data lake can quickly turn into a data swamp, where trusted data is difficult to find, and the vast majority of data remains underutilized and insecure.
Organizations should implement best practices such as:
Data Cataloging: Use metadata to catalog data assets, making it easier for users to discover, understand, and use the data stored in the lake.
Data Quality Management: Regularly clean, validate, and enrich data to ensure it remains useful and accurate.
Access Controls: Implement role-based access controls to protect sensitive data and ensure that users only have access to the data they need.
Data Governance: Define and enforce policies for data management to maintain control, ensure data quality, and comply with regulations.
Governance in data lakes: ensuring control and compliance
Without proper governance, a data lake can quickly become a data swamp—a disorganized, unusable centralized repository of data. Organizations are tasked to manage the governance in data lakes to maintain control, ensure data quality, and comply with regulations.
Data governance provides effective data lifecycle management by using policies, processes and best practices to manage data. It consists of numerous processes including data quality management, data stewardship, access control, data lineage, and regulatory compliance., Governance is essential to maintain data integrity and meet regulatory compliance needs.
Key characteristics of data lake governance
To ensure your data-lake data is properly governed, ensure you have the following practices in place:
Data cataloging and metadata management
A robust data catalog provides a centralized inventory of all data assets, along with metadata that describes the data's origin, structure, and usage.
Data cataloging allows users to efficiently discover, comprehend, and leverage the data stored in the lake. It also facilitates data lineage, enabling the tracking of data as it undergoes various transformations, ensuring both transparency and traceability.
Data quality management
Data quality is critical in a data lake environment where data is ingested in its raw form from varied resources. Bad data-quality data can lead to erroneous business decisions and inaccurate results.
By focusing on data quality, organizations can minimize errors, build greater trust in their data, and achieve improved business results.
Access control and data security
With the diverse and often sensitive nature of data stored in a data lake, robust access controls and security measures are essential. This includes role-based access control (RBAC), encryption, and auditing.
Effective access control ensures that only authorized users can access sensitive data, reducing the risk of data breaches. Encryption protects data at rest and in transit, while auditing provides a record of who accessed what data and when, supporting accountability.
Compliance and regulatory adherence
Data lakes often contain personal, financial, or health-related information subject to regulations such as GDPR, HIPAA, or CCPA. Ensuring compliance with these regulations is critical to avoid legal penalties and maintain customer trust.
Governance frameworks that include compliance checks and automated reporting help organizations meet regulatory requirements, protect sensitive data, and avoid costly fines.
Data stewardship and ownership
Data stewardship involves assigning specific roles and responsibilities for managing data assets. This includes identifying data owners, who are responsible for the data's overall accountability, and data stewards, who oversee the daily management and operations of the data.
Clear data stewardship roles ensure that data is properly maintained, documented, and used, preventing issues like data duplication, inconsistency, and unauthorized access.
Data lifecycle management:
Data lifecycle management involves defining policies for how data is stored, archived, and eventually deleted. This is crucial in a data lake, where data volumes can grow rapidly.
Effective lifecycle management helps control storage costs, ensure data relevance, and comply with data retention regulations. It also prevents the accumulation of obsolete or redundant data, keeping the data lake clean and efficient.
How Alation can help you govern your data lake
As a platform for data governance, Alation guides people to adopt governance best practices within their workflows. By embedding governance policies, standards, and terms in data consumers’ normal activities, people get the information they need to leverage data compliantly. This iterative process ensures continuous data management and improvement in data behaviors. Community participants are central to this process, as they both consume and layer in new knowledge, while stewards guide them based on standards and policies.
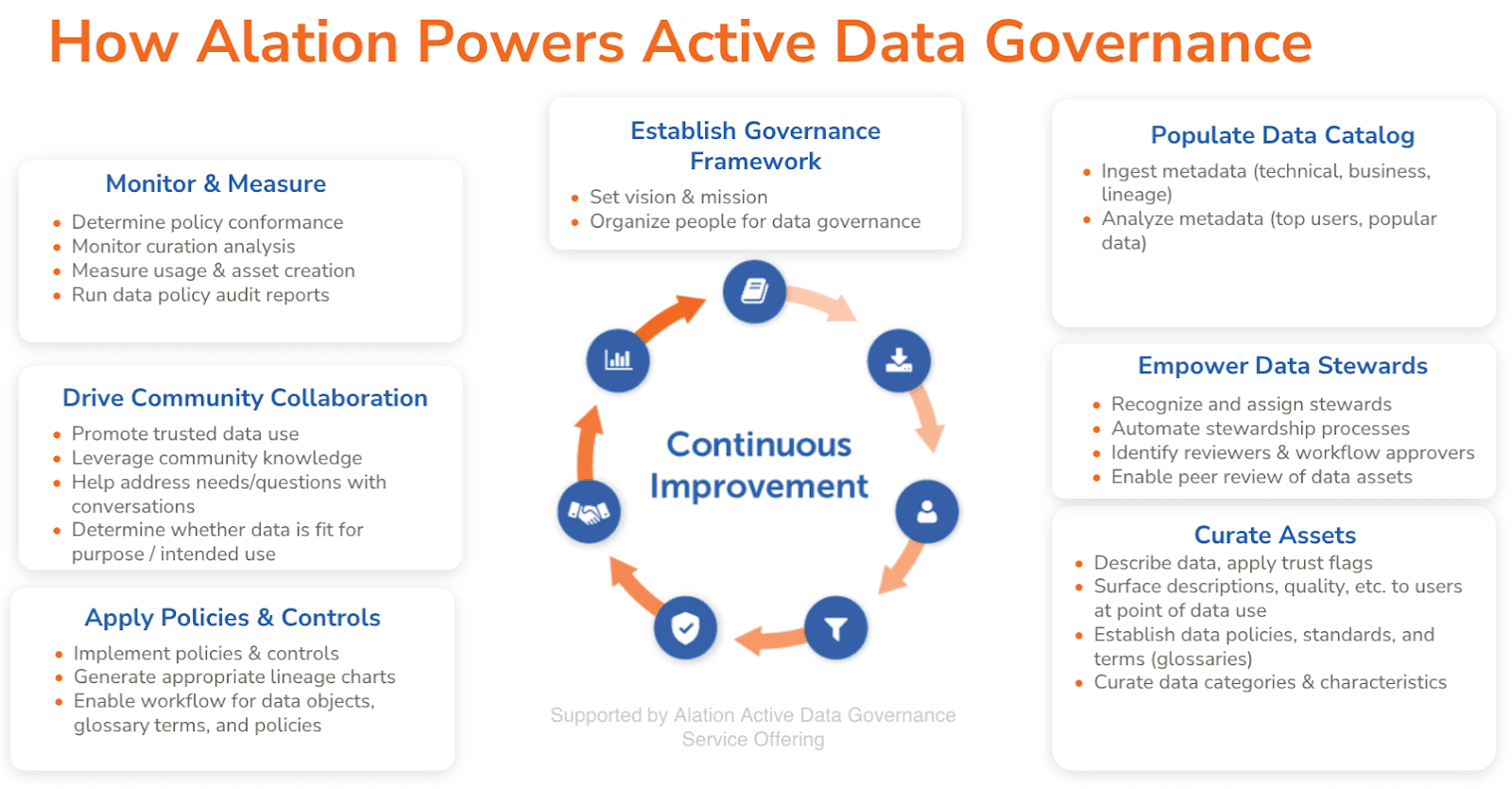
The future of data lake governance
As data lakes continue to evolve, so too will the governance strategies needed to manage them effectively. The rise of artificial intelligence and machine learning will likely play a significant role in automating and enhancing governance practices, enabling organizations to manage data more intelligently and proactively. Moreover, as regulations become increasingly stringent, the importance of robust governance frameworks will only grow.
In conclusion, data governance is a critical component of any successful data lake implementation. By establishing clear policies, automating processes, and involving stakeholders, organizations can maintain control over their data, ensure compliance, and unlock the full potential of their data lakes.
Curious to learn how you can implement data governance for your organization’s data lake? Book a demo with us to learn more.
- What is a data lake?
- Key characteristics of a data lake
- Data lake use cases
- Benefits of using a data lake
- Best practices of data lake management
- How Alation can help you govern your data lake
- The future of data lake governance
Contents
Tagged with
Loading...