The Data Scientist’s Guide to the Data Catalog in 2025
Published on January 31, 2025

In today’s data-driven world, data scientists are rock stars as they shape the future and command top salaries. But even these heavy hitters have a common obstacle: finding and trusting the right data to do their jobs.
In this article, we will explore how data scientists are using data catalogs to transform how they work. We’ll show how data catalogs turn a previously frustrating hunt for data into a streamlined, efficient process that accelerates the insights data scientists deliver to help organizations grow.
Key takeaways
Data catalogs streamline every stage of the data science process, from discovery and collaboration to visualization and governance, to boost efficiency and productivity.
Data scientists use data catalogs to ask better questions and find the resources to get those questions answered.
Data scientists can quickly locate and access needed data using a data catalog without wasting time on the wrong data or searching for expertise.
Data silos can be bypassed and broken down with a data catalog so data scientists can better collaborate with each other and other teams.
Data catalogs help feed good data-hungry organizations and innovations like AI and ML while providing impressive and proven returns on investment.
Data scientists are in high demand, with job growth for data science roles expected to be “much faster than average” at 36% over the next decade, according to the U.S. Bureau of Labor Statistics.
A shortage of data science talent, especially in traditional industries, has organizations struggling to compete with new, digital disrupters and those building a robust data culture. Data scientists command an average salary of nearly $125,000, with entry-level data scientists earning $83,000 on average. That compares very, very favorably to the average starting salary for last year’s freshly-minted college graduates of just over $68,000.
Data scientists struggle to find and understand data
Even with high pay, advanced education, and a rush to hire more data scientists, organizations aren’t realizing the value of these expensive experts. With increasing data needs to feed artificial intelligence (AI) and machine learning (ML) innovations, and the ever-increasing need to be data-driven, data science teams encounter many of the same hurdles that plagued data analytics teams in years past:
Finding trusted, valuable data is a time-consuming and highly manual process.
User roles, permissions, and approval requests create obstacles that prevent speedy data access.
Understanding data requires expertise in the specific data sets, which requires more time and more people as data stewards.
The last point on locating those who understand the data is to answer the ultimate question of “Who knows this data best?” but also questions like:
Why was this data set created?
Who created it?
Is this data trustworthy?
How do I know it can be trusted?
How can I use this data?
Who has used it in the past and what can they tell me about it?
For these reasons and many more, finding and evaluating data takes up much of a data scientist’s time. Instead of spending their days putting to work their unique skillsets and algorithmic knowledge, data scientists are stuck sorting through data sets, trying to determine what’s trustworthy, and evaluating how best to use that data for their own goals.
Fortunately, just as data catalogs help solve the problems of discovery and exploration for data analysts, they can aid data science teams.
Streamlining the data science workflow
The traditional data science workflow, as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps:
Ask a question
Get the data
Explore the data
Model the data
Communicate and visualize the results
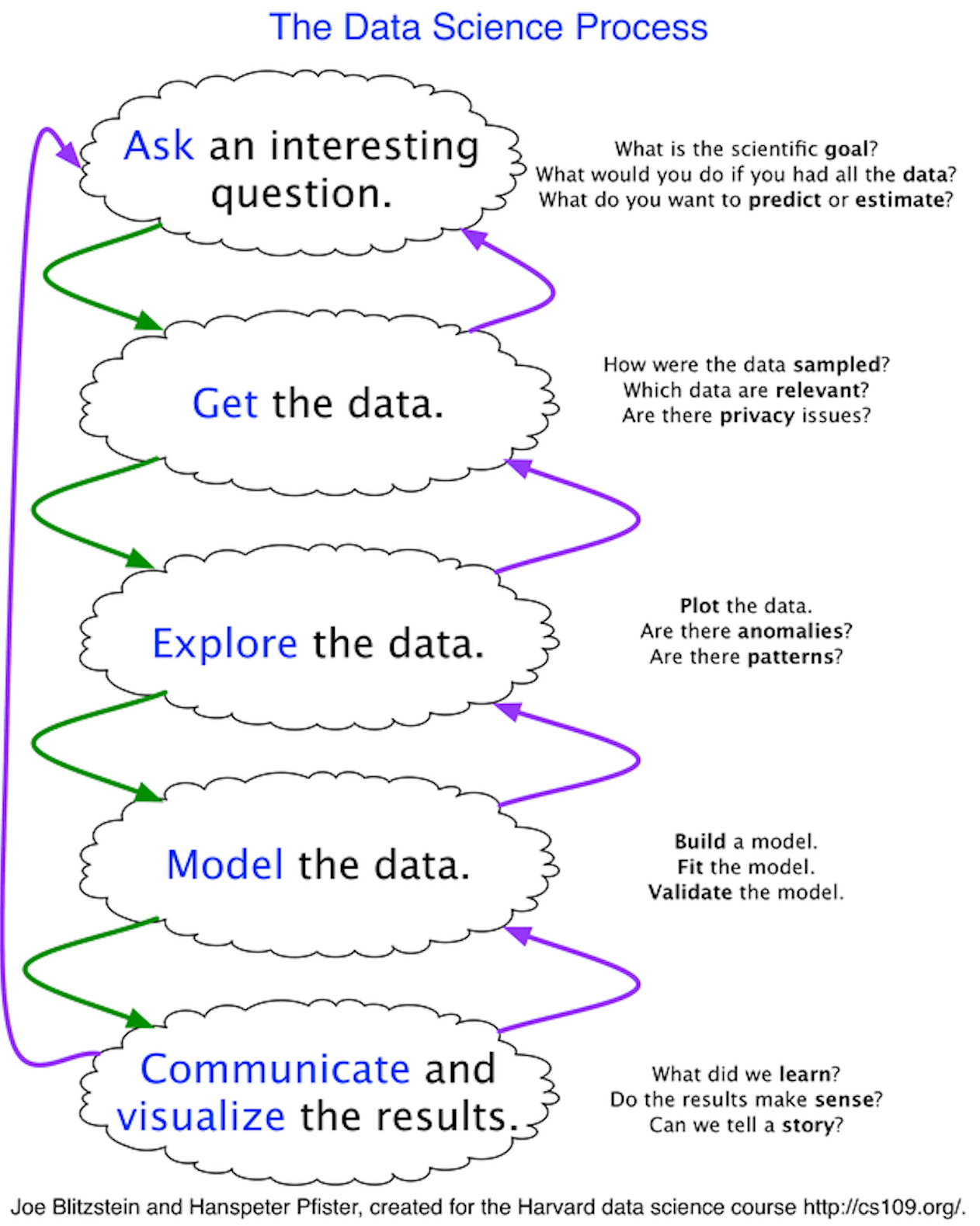
A data catalog can assist directly with every step except model development. Even then, information from the data catalog can be transferred to a model connector, allowing data scientists to benefit from curated metadata within those platforms.
Here’s how data scientists’ workflows might differ when using or not using a data catalog:
Traditional data science workflow | Data catalog-enabled data science workflow |
Search for required data manually Overcome data silo roadblocks Clean data, not knowing if it’s already been cleaned Slowly understand the data Finally, provide insights | Use a single source to find required data quickly Understand the data and any required pre-processing Deliver insights |
An example of using a data catalog to accelerate data discovery and usage comes from Vattenfall, one of Europe’s largest and most forward-thinking power generation and distribution companies. Prior to deploying a data catalog, Vattenfall’s data was locked in silos, and knowledge about the data was locked in the heads of individual workers spread across the organization.
Today, it uses Alation as its data intelligence platform for data search and discovery, giving more than 500 workers a single source of truth for finding and understanding its data.
“Before Alation, we saw a lot of silos and individual documentation—and the risks and inefficiencies associated with that,” says Sebastian Kaus, Vattenfall's Data Governance Lead. “After implementing Alation, we see more collaboration and we see more discussions. For the enterprise, Alation is the single source of truth.”
Read more about how a data catalog helps Vattenfall.
3 ways data catalogs help data scientists ask (and answer!) better questions
A data scientist begins by asking a big question. In fact, Stefano Puntoni, PhD and the Sebastian S. Kresge Professor of Marketing at The Wharton School, says, “[C]rafting the right questions is an essential and foundational step in the data-analysis process.”
A data catalog provides a holistic, navigable view of an organization’s data. As a result, a data scientist can quickly browse through curated data to determine which questions they can answer, and which questions would require the acquisition of additional data.
A data catalog can also serve as a source of inspiration for data scientists. Because a catalog allows domain experts or data stewards to comment on and describe the data assets they know best, those experts can suggest potential questions a given data set might be able to answer. In this way, a data scientist benefits from business knowledge that they might not otherwise have access to. The catalog facilitates the synergy of the domain experts’ subject matter expertise with the data scientists statistical and coding expertise.
A data catalog can help data scientists find answers to their questions (and avoid re-asking questions that have already been answered). Modern data catalogs surface a wide range of data asset types. For instance, Alation can return wiki-like articles, conversations, and business intelligence objects, in addition to traditional tables.
When data scientists ask questions, it captures what the data scientist wants to model or predict. It requires them to frame their project and articulate their goals. Corporate data scientists rely on the data their organizations possess, so their questions are limited by the data that’s available to them. That context is important: It’s no good asking a question that they don’t have the means to answer.
For example, a new data scientist who is curious about which customers are most likely to be repeat buyers might search for customer data only to discover an article documenting a previous project that answered their exact question.
Documenting data science projects and providing access to data experts in a data catalog saves time and prevents data scientists from wasting resources on duplicate projects. It also empowers newcomers to onboard more quickly using curated expertise to aid rapid understanding.
Efficient strategies to acquire data
Increasingly, data catalogs not only provide the location of data assets but also the means to find and access data. A data scientist can use a data catalog to identify several assets that might be relevant to their question and then use a built-in SQL query editor, like Alation Compose, to access the data.
Query editors embedded directly into data catalogs have a few advantages for data scientists. They leverage the metadata the catalog stores about the assets being queried, allowing them to suggest column titles, surface warnings, or endorsements for particular data assets, or even pull up the relevant data usage policies. This creates a second layer of governance to ensure the data scientist is using the right data in ways that are permitted.
Query editors also help with time-saving collaboration. Data catalogs provide a means for publishing and sharing SQL queries across the organization, reducing duplication of effort.
Using data must be done with confidence, however, especially as more data is used with AI and ML applications that expose organizations to new data governance risks. That’s why data governance and compliance are critical components of data discovery. However, data scientists shouldn’t be burdened with understanding and applying policies. Data catalogs can be applied to data governance, too, to discover and classify sensitive data, guide workers in using data properly, and improving data compliance across the organization with automation features that enforce privacy policies such as data masking, for example.
Improving data discovery and exploration for data scientists
To use data, workers must first find the data. That’s not easy. Research shows that the average worker spends 3.6 hours daily searching for information. That’s nearly half of the typical workday. It’s worse for IT employees who spend more than half their day (4.2 hours!) searching for data.
Oh, but that’s nothing. Data practitioners like data scientists might spend as much as 80% of their workday wrangling data according to mathematician and diginomica contributing analyst Neil Raden.
Once data scientists locate what they’re seeking, they will ultimately want to plot the data directly in a Python or R notebook to play around with it. Data catalogs give them a jump start on this exploration phase.
Data catalogs provide much more than just business knowledge about data assets; they compile a range of information, including statistical summaries of data assets. Rather than having to export the data to determine attributes, such as the cardinality, mean, number of nulls, and so on, a data scientist can see all of that information right on the asset's profile. So instead of wasting their time recalculating that information (using pandas, numPy, or other statistics packages), the data scientist can dive right into the interesting parts of modeling their data more quickly.
Modern data catalogs also facilitate data quality checks. Historically restricted to the purview of data engineers, data quality information is essential for all user groups to see. Alation’s Open Data Quality Initiative is a great example of a data catalog partnering with purpose-built data quality tools to surface data quality metrics for all users, freeing engineers from playing data middlemen and gatekeepers.
Visualizing and communicating results for impact
A key component of data scientists’s role is communicating their findings. That’s not always easy with non-technical audiences. Telling data’s story with visualizations assisted by a data catalog, however, makes it easier to understand.
Data catalogs can help data scientists promulgate the results of their projects. As referenced above, modern data catalogs often support an asset type, like an article or a project page, which allows data scientists to capture their work as its own discoverable entity. The data scientist can write text, copy and paste code, and embed visualizations into these assets, creating a living document others can reference in the future.
Cataloging data science projects in this way is critical to helping them generate value for the company. Instead of findings disappearing into thin air after a presentation, the results and the methodology will be available and discoverable indefinitely—an invaluable asset to an organization's corpus of knowledge about data.
For more on integrating data visualizations and data catalogs, read “5 Benefits of Data Visualization: Why Integrating a Data Catalog is Crucial.”
Embracing data catalogs
Data scientists often have different requirements for a data catalog than data analysts. Although there is significant overlap between their workflows, data scientists often rely on raw data stored in a data lake rather than the highly structured data in a data warehouse, which is the realm of the analyst. Thus, it’s important to select a data catalog that can meet the technical needs of both groups, and other teams, too.
A modern data catalog extracts metadata from a wide range of sources and supports many different data and asset types, allowing a single tool to serve both data scientists and data analysts, along with a range of other users. By bringing together and documenting the expertise of all groups in a shared platform, a data catalog can help data analysts, engineers, data scientists, and every worker engaged with data learn from one another on a collaborative platform.
Measuring the ROI of data catalogs
Forrester Consulting worked with several Alation customers to conduct a Total Economic Impact™ (TEI) study that examined the ROI enterprises realized by deploying a data catalog. The quantitative ROI benefits of data catalog adoption, data catalog customers achieved:
364% return on investment (ROI)
$2.7 million in time saved due to shortened data discovery
$584,182 savings from business user productivity improvement
$286,085 savings from shortening the onboarding of new analysts by at least 50%
Qualitative benefits include preventing data lakes from turning into data swamps, improving the accuracy of analytics, and facilitating the documentation of organizational knowledge.
The future is now: Data scientists reap the benefits of data catalogs
Data catalogs provide a huge boost to data science workflows. Embracing the data catalog isn’t just a smart move; it’s a strategic imperative in 2025 and beyond.
Organizations that integrate data catalogs help data scientists discover data faster, improve data quality, enhance data collaboration, improve data governance, and more. There’s also no reason to wait on a data catalog, since the ROI is proven and impressive. And, as AI and ML enters the workflows of data scientists, having a better understanding of data will improve AI outcomes and increase the returns on investment in these modern innovations.
To get started with your own data catalog, read our how-to guide for implementing Alation.
- Key takeaways
- Data scientists struggle to find and understand data
- Streamlining the data science workflow
- 3 ways data catalogs help data scientists ask (and answer!) better questions
- Efficient strategies to acquire data
- Improving data discovery and exploration for data scientists
- Visualizing and communicating results for impact
- Embracing data catalogs
- Measuring the ROI of data catalogs
- The future is now: Data scientists reap the benefits of data catalogs
Contents
Tagged with
Loading...