Data Mesh vs. Data Fabric: A Love Story

By Mitesh Shah
Published on January 13, 2022

There have been many great rivalries over the years. Yankees vs Red Sox. Barcelona vs Real Madrid. Tyson vs Holyfield. And now, arguably the greatest rivalry the world (well, at least the data community) has ever witnessed: Data Fabric vs Data Mesh! Grab the popcorn. We’ll save you the $80 pay-per-view fee and give you a front-row seat into this exciting match up.
Data fabric and data mesh are both having a moment. Gartner calls data fabric the Future of Data Management. Thoughtworks says data mesh is key to moving beyond a monolithic data lake. But which one is right? Which one is better? Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary.
Data fabric has captured most of the limelight; it focuses on the technologies required to support metadata-driven use cases across hybrid and multi-cloud environments. Data mesh, on the other hand, takes a more people- and process-centric view. Data mesh forgoes technology edicts and instead argues for “decentralized data ownership” and the need to treat “data as a product”. This approach, Thoughtworks argues, overcomes the bottlenecks and disconnects that are typical of data lake and data warehouse environments — disconnects that arise as data engineers play middle-men between data producers and consumers.
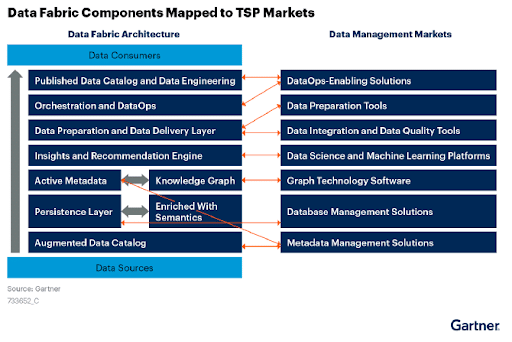
Gartner on Data Fabric
Moreover, data catalogs play a central role in both data fabric and data mesh. Gartner is explicit that an augmented data catalog is foundational to a data fabric. Indeed, a data catalog plays a crucial role in extracting and analyzing metadata from an organization’s data sources to fuel the data fabric. (See diagram below.)
Thoughtworks on Data Mesh
For data mesh, too, the experts agree a platform is essential. Thoughtworks calls out the need for a “self-serve data platform” to ensure teams can autonomously own their data products. A data catalog is not specified by name since the data mesh is technology-agnostic. But make no mistake: A data catalog addresses many of the underlying needs of this self-serve data platform, including the need to empower users with self-serve discovery and exploration of data products.
There is a lot to unpack here. And we’re going to do just that. In this blog series, we’ll offer deep definitions of data fabric and data mesh, and the motivations for each. (We all know the terms here can get pretty technical pretty fast, so we’ll do our best to use plain language.) In part 2 of this series, we’ll do a deep dive on data fabric and the role of the data catalog within. In part 3, we will do the same for data mesh. And we’ll conclude in part 4 with practical steps that can be taken to blend these design and architectural concepts together to get faster, more reliable value from your data.
We know you came for a boxing match. We hope you’ll stay for the love story. Let’s go!
What Is a Data Fabric?
Well, it depends on who you ask. There are vendors out there that will have you believe their product is an example of a data fabric — some even have ‘Data Fabric’ in their product name. All of this is no doubt well-intentioned, but it does confuse the market. The definition we are going with here is Gartner’s and, to them, there is no single vendor that addresses the complete set of needs required to build a data fabric (at least not today). Gartner defines data fabric as a “design concept that serves as an integrated layer (fabric) of data and connecting processes.”
A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets to support the design, deployment and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.
We’ll dig into this definition in a bit. For now, note these important key words: integrated and reusable data. This, in essence, is the goal of a data fabric. At the core of data fabric is the intelligent analysis of metadata supporting a smarter system of integration, enabling trusted and reusable data to be leveraged by the widest possible group of consumers – humans and machines alike.
Let’s turn now to the rest of the definition. Gartner says a data fabric is a design concept. In other words, a data fabric is not a single thing or product. It is instead composable, made up of a set of integrated technologies that accelerate value from enterprise metadata. Gartner also acknowledges that data is sitting everywhere today in hybrid and multi-cloud environments (which, at this point, should go without saying.)
Design concept. Metadata. Hybrid and multi-cloud. These are the important terms in Gartner’s definition, but let’s put it all together by articulating the rationale for why a data fabric is needed in the first place.
Why Do You Need a Data Fabric?
With so much complexity emerging from data landscapes, people need a means to find trusted data alongside guidance on how to use it. The key is to capture wisdom in the community. Both data fabric and mesh enable people to use and reuse data by making the most valuable assets the most visible for wider use. This empowers newcomers to leverage insights and integrations others have built before them. It also ensures that established knowledge (and valuable processes) are woven into the system of data distribution.
But how do you identify the best data, and best practices for using it? The key is metadata. Metadata is the key to fueling data intelligence use cases across the board, including data search & discovery and data governance. Metadata (or “data about data”) captures the who, what, where, when, and how of every asset – to flesh out its “why” – and helps newcomers understand and use that asset more quickly. But accessing and making sense of metadata is extremely challenging in today’s environment.
A big reason is that metadata is everywhere. It’s in all types of data management systems, from databases to ERP tools, to data integration software. And metadata could be sitting in many different locations, including on-premises, in the cloud, and everywhere in between.
Humans are hard-pressed to find relevant metadata, let alone make sense of it. Data fabric, says Gartner, is the answer. By using technologies to automate the discovery and continuous analysis and reuse of metadata, organizations will overcome the challenges associated with its proliferation and reduce the error-prone manual efforts that go with making sense of it. These technologies are broadly categorized as data intelligence solutions.
In fact, data intelligence technologies support building a data fabric and realizing a data mesh. As a discipline, data intelligence weaves together “the traditional categories of metadata management, data quality, data governance, master data management, data profiling, and data privacy while incorporating intelligence derived from active metadata.”
Let’s turn our attention now to data mesh.
What Is a Data Mesh?
Zhamak Dehghani of Thoughtworks is widely credited with having conceived of data mesh in a blog post back in May 2019. Follow-up blogs clarify architectural aspects of data mesh, but all remain true to the founding vision and approach first introduced in 2019. Vendors are now putting their own spin on data mesh, which will no doubt introduce some confusion. Yet these vendors universally cite the work of Dehghani and Thoughtworks as the basis for their “take” on data mesh.
The origin story is clear, but a concise definition is harder to come by. (Most of Deghani’s public write-ups focus on motivating the data mesh and key principles of the data mesh architecture.) Fortunately, Arif Wider, also at Thoughtworks, offers a clear definition:
The data mesh paradigm is a strong candidate to supersede the data lake as the dominant architectural pattern in data and analytics. Importantly, the data mesh mainly introduces a new organizational perspective and is independent of specific technologies.
Here, Wider calls for a new architectural approach, one that will supersede the data lake. But why?
Why Do You Need a Data Mesh?
Much has been written about how data lakes have failed us all. How they’ve turned into data swamps due to lack of organization, governance, and accessibility. For Wider, the underlying issue with data lakes is straightforward and can be captured in one word: centralization.
A central team is responsible for maintaining the central infrastructure (AKA the data lake). This team is usually disconnected from the needs of data consumers and often lacks the domain expertise of data producers. Yet here they are, forced to play middle-men between consumers and producers because the prevailing data lake architecture forces the teams to be organized this way. The end result is a team that doesn’t scale and data being served up to consumers which may or may not meet their quality needs.
Data mesh inverts this model with domain-driven design and product thinking. Responsibilities are distributed to the people who are closest to the data. These product owners are responsible for delivering data as a product and, as such, they are accountable for objective measures, including “data quality, decreased lead time of data consumption, and general data user satisfaction…”
In other words, data mesh is all about people, calling for a shift in responsibilities to ensure high quality data is put in the hands of data consumers faster and more efficiently. As we’ll see in parts 3 and 4 of this series, however, technology does play a very important enabling role.
In Conclusion
Are you curious to learn more? Because there’s much more to unpack. In this blog series, we’ll explore in-depth how data fabric and data mesh can work together. Up next: let’s turn our attention back to data fabric, its key pillars, and the role of the data catalog within. Stay tuned for this blog early in 2022!
New to data catalogs? This white paper, How to Evaluate a Data Catalog, walks you through what to look for.
1. https://www.gartner.com/document/3994025
2. https://martinfowler.com/articles/data-monolith-to-mesh.html
3. https://www.thoughtworks.com/en-us/insights/blog/data-mesh-its-not-about-tech-its-about-ownership-and-communication
4. https://www.gartner.com/smarterwithgartner/data-fabric-architecture-is-key-to-modernizing-data-management-and-integration
5. Though a single product could support elements of the entire data fabric stack
6. See blog 2 for a deep dive on the technologies involved.
7. https://www.forbes.com/sites/forbestechcouncil/2021/01/28/what-is-data-intelligence-and-how-can-it-help-your-organization/?sh=46313f1e4033
8. https://martinfowler.com/articles/data-monolith-to-mesh.html
9. https://www.thoughtworks.com/en-us/insights/blog/data-mesh-its-not-about-tech-its-about-ownership-and-communication
10.https://martinfowler.com/articles/data-mesh-principles.html#DomainOwnership
- Gartner on Data Fabric
- Thoughtworks on Data Mesh
- What Is a Data Fabric?
- Why Do You Need a Data Fabric?
- What Is a Data Mesh?
- Why Do You Need a Data Mesh?
- In Conclusion








