

In 2026, businesses are racing to operationalize both software and data faster than ever. Research predicts that over half of enterprises will adopt agile, collaborative DataOps practices by 2026. Meanwhile, DevOps practices have become deeply entrenched: in one global survey, 13 of 14 core DevOps practices were already adopted by at least half of respondents. Yet, despite their similar-sounding names and shared agile principles, DataOps and DevOps serve very different missions.
As AI-driven applications and data products become core to enterprise value creation, understanding the distinction between DataOps and DevOps is essential. While DevOps optimizes software delivery pipelines, DataOps ensures that the data feeding those systems is accurate, accessible, and trustworthy—the foundation for modern AI and analytics.
This guide unpacks the similarities, differences, use cases, and best practices of both methodologies—and shows how platforms like Alation’s Data Intelligence Platform can supercharge your DataOps journey.
Key Takeaways
DevOps focuses on accelerating and automating software delivery; DataOps focuses on accelerating and automating the flow of data for analytics and AI.
Both disciplines rely on agile cycles, automation, and collaboration across traditionally siloed teams.
DataOps introduces unique challenges—governance, quality, lineage, and compliance—that are critical in data-driven enterprises.
AI and metadata management are emerging as the next evolution of DataOps automation.
Platforms like Alation enable trusted DataOps by integrating data discovery, lineage, and stewardship into every stage of the data lifecycle.
An Overview of DataOps vs. DevOps
Both DataOps and DevOps were born from a need to deliver faster results without sacrificing quality. Each draws inspiration from agile methodologies, continuous integration, and lean manufacturing principles.
The main difference? DevOps accelerates software development and deployment, while DataOps accelerates data delivery, transformation, and analytics.
What is DevOps?
DevOps is a methodology that unites software development and operations to streamline the process of building, testing, deploying, and maintaining applications.
Originally pioneered by tech giants like Google and Amazon, DevOps was a response to the need for faster, more reliable software releases. Traditional waterfall methods—where developers wrote code and “threw it over the wall” to operations—created bottlenecks. DevOps solved this by encouraging continuous integration (CI) and continuous delivery (CD), creating a loop of constant improvement:
Develop: Engineers plan, code, and build features.
Integrate & Test: Code is integrated and tested automatically.
Deploy: Operations deploys the product to production environments.
Monitor & Feedback: User feedback informs new iterations.
The result is a shorter release cycle, better quality control, and improved collaboration between teams once separated by function.

What Is DataOps?
DataOps applies similar principles—but to data rather than software. It brings together data engineers, data scientists, analysts, and business users to deliver trusted, high-quality data products faster.
DataOps is a process-oriented methodology that unites people, processes, and technology to improve the quality, speed, and reliability of analytics and AI outcomes. It draws from lean manufacturing, DevOps, and agile development but focuses on ensuring that data—constantly changing, messy, and distributed—can be transformed into value efficiently.
In practice, DataOps involves:
Automating data pipelines across ingestion, transformation, and delivery.
Testing and validating data quality continuously.
Tracking lineage to ensure transparency and trust.
Collaborating across teams to align data initiatives with business outcomes.
When done right, DataOps enables organizations to go from data need to data success faster—and with confidence that insights are built on solid foundations.
What Are the Differences Between DataOps and DevOps?
While both methodologies aim to increase efficiency and agility, the outputs, challenges, and teams involved differ significantly.
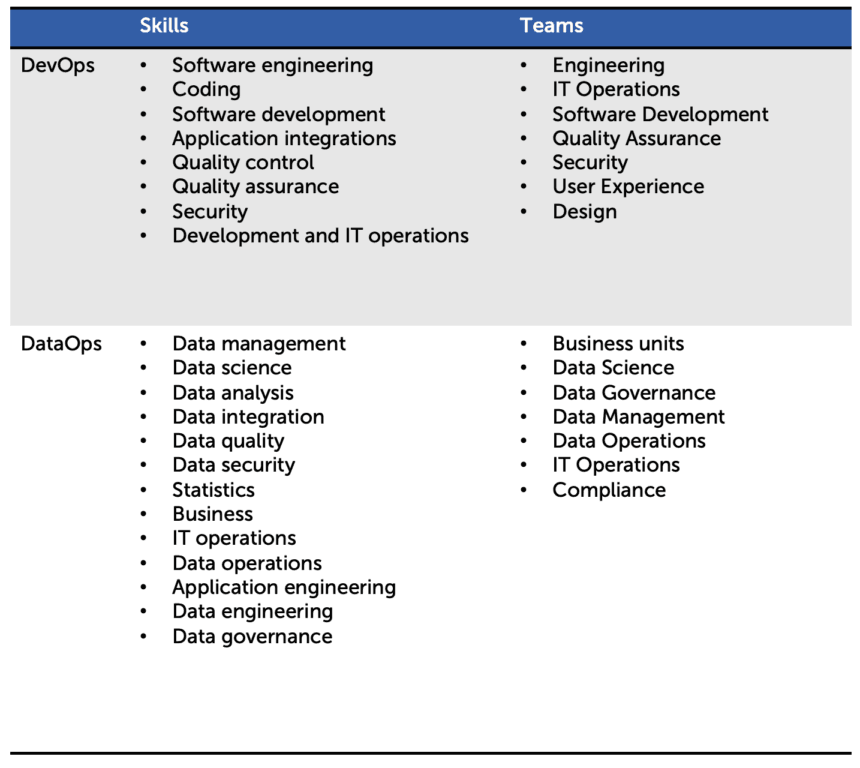
Skill & Team Requirements
DevOps teams typically include software developers, IT operations professionals, quality assurance testers, and site reliability engineers. Their shared goal is to streamline software release cycles and minimize downtime. They focus on continuous delivery, version control, and the optimization of the development lifecycle.
DataOps, on the other hand, draws from a wider range of expertise. Data teams include data engineers, data scientists, data analysts, governance specialists, and operations teams. Their mission is to orchestrate reliable data pipelines that support analytics, big data workloads, and AI initiatives.
This requires a deep understanding of data management, data integration, and orchestration frameworks. While DevOps focuses on software releases and new features, DataOps focuses on continuous data processing and quality assurance across distributed systems. The collaboration between data teams and operations teams is crucial to maintain compliance, scalability, and performance.
Ultimately, DevOps is rooted in optimizing the DevOps methodology for software efficiency, whereas DataOps extends this mindset to the world of data, where variability, governance, and scale introduce entirely new challenges.
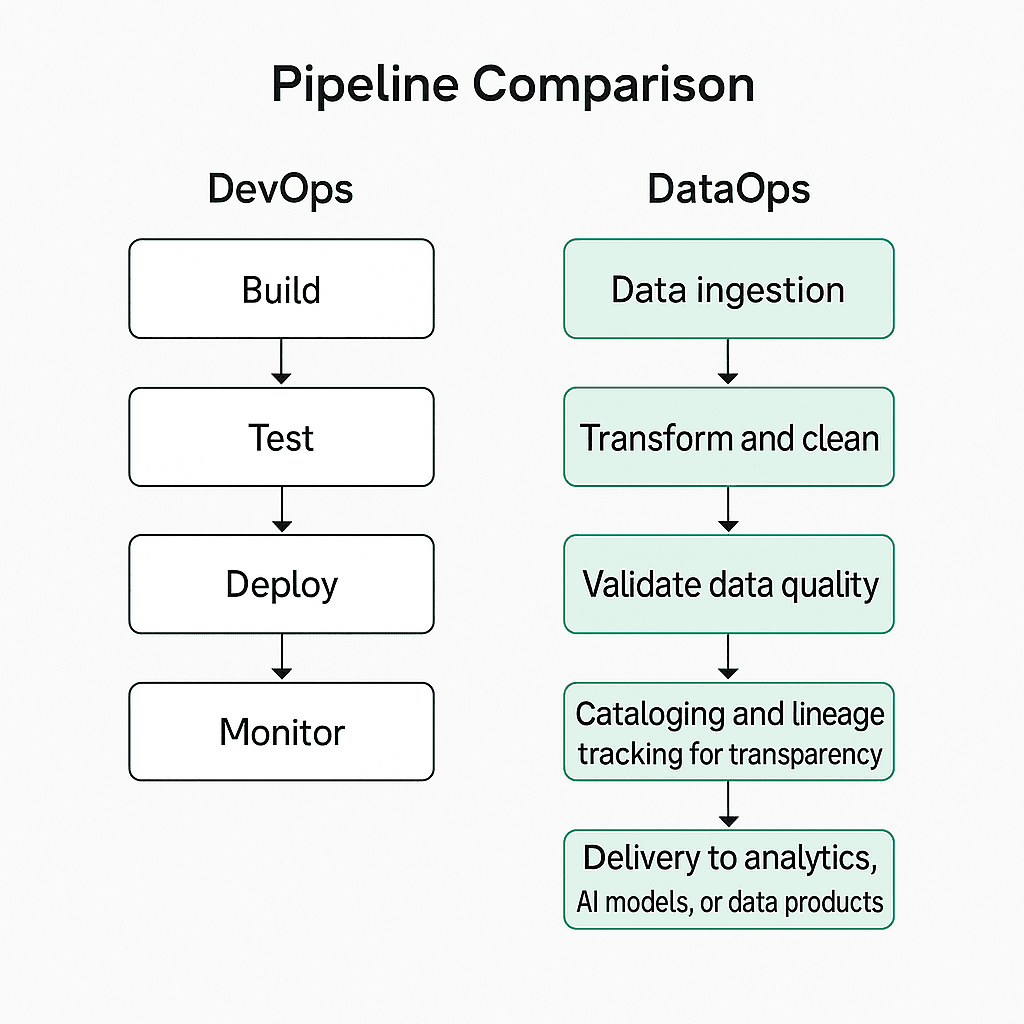
Pipeline Comparison
The DevOps pipeline is well-defined and predictable. It follows a straightforward sequence: build → test → deploy → monitor.
The DataOps pipeline is more complex because it must handle ever-changing data sources, schemas, and business needs. It includes:
Data ingestion from multiple systems (cloud, on-premises, APIs).
Transformation and cleaning, often involving AI-assisted tools.
Validation to ensure data meets quality thresholds.
Cataloging and lineage tracking for transparency.
Delivery to analytics, AI models, or data products.
Where DevOps focuses on releasing a static product efficiently, DataOps focuses on managing a dynamic flow of data across the enterprise—one that constantly evolves as new sources and technologies emerge.
What Are the Similarities Between DataOps and DevOps?
Despite their differences, DataOps and DevOps share core philosophies that drive speed, collaboration, and continuous improvement.
Both disciplines:
Break down silos between development, operations, and data teams.
Use automation to increase reliability and consistency.
Employ continuous feedback loops to iterate faster.
Emphasize monitoring and observability to maintain performance and reduce downtime.
Leverage orchestration tools to coordinate complex workflows efficiently.
Together, these shared principles enable organizations to achieve agility at scale. Whether the goal is to release new features quickly or deliver trusted data products, both methodologies rely on disciplined automation, collaboration, and governance. As AI and MLOps expand, the boundaries between DataOps and DevOps will continue to blur, creating a unified approach to innovation across data and software ecosystems.
Use of Agile Cycles
Both DataOps and DevOps rely on agile methodologies—short, iterative cycles that enable rapid delivery and adaptation.
For DevOps, agile means smaller, more frequent software releases. For DataOps, agile means continuously improving data pipelines and analytics outputs.
Agile also enables early error detection and fast course correction, reducing the time spent troubleshooting issues downstream.
However, DataOps introduces an extra layer of complexity: governance. Because data is constantly changing, maintaining high-quality inputs requires active data governance—a non-invasive, collaborative framework that ensures only trusted data enters the analytics process.
Use of AI
By 2026, both DataOps and DevOps heavily leverage AI and machine learning to automate processes.
In DevOps: AI helps with predictive monitoring, performance optimization, and anomaly detection in code deployments.
In DataOps: AI automates data quality checks, identifies schema drift, and flags anomalies in real-time data streams.
In both disciplines, AI copilots are emerging to assist engineers and analysts by automating repetitive tasks and offering intelligent recommendations.
What Are the Top Use Cases for DataOps and DevOps?
Both methodologies have broad applications across industries—but their use cases differ according to their core missions.
DataOps Use Cases
Automating Data Pipelines for AI and Analytics: Streamline ingestion, transformation, and delivery of data to machine learning models or BI dashboards.
Enhancing Data Quality and Governance: Use DataOps frameworks to validate and monitor data quality continuously—essential for compliance with regulations like GDPR, BCBS 239, and the MAS guidelines.
Enabling Self-Service Analytics: Democratize data access so that business users can find, understand, and trust data without IT bottlenecks.
Supporting Data Product Development: Treat data assets as products—complete with owners, SLAs, and metrics—to ensure they deliver measurable business value.
Accelerating Cloud Data Modernization: Migrate legacy systems to modern data platforms while maintaining reliability, lineage, and security.
These use cases illustrate how DataOps drives efficiency in data management and analytics operations. As organizations scale their AI and MLOps initiatives, DataOps becomes the backbone of sustainable innovation, ensuring data is always ready for decision-making and model training.
DevOps Use Cases
Continuous Integration and Deployment (CI/CD): Automate the process of building, testing, and deploying code to accelerate release cycles.
Infrastructure as Code (IaC): Manage and provision infrastructure automatically through code, ensuring consistency and scalability.
Security and Compliance Automation: Embed security checks into every stage of the software lifecycle—an emerging discipline known as DevSecOps.
Cloud-Native Application Development: Enable rapid deployment of microservices and containerized applications across cloud environments.
Monitoring and Performance Optimization: Use observability tools to detect performance issues, ensuring software reliability and uptime.
Together, these use cases show how DevOps revolutionized the development lifecycle—helping organizations release new features faster, reduce downtime, and maintain continuous improvement. As enterprises merge data and software capabilities, many are now extending these same principles into DataOps for unified operations.
Best Practices for DataOps Implementation
Modern enterprises increasingly view DataOps as the backbone of data-driven decision-making and AI readiness. To get it right, organizations should combine automation, collaboration, and governance.
Define DataOps Objectives Aligned with Business Goals
Start by identifying what “data success” means for your organization. Is it faster time to insight? Better data quality? Improved trust?
DataOps should not be implemented in isolation—it must align with business objectives such as reducing compliance risk, improving AI accuracy, or enabling self-service analytics.
Automate Data Pipelines and Processing Tasks
Automation lies at the heart of DataOps excellence. Data teams should implement end-to-end orchestration and automation across ingestion, transformation, and validation processes. This ensures that data integration and processing tasks remain consistent, scalable, and version-controlled.
By automating these workflows, operations teams can reduce downtime, eliminate manual handoffs, and improve observability. Modern DataOps tools enable data engineers to automate testing and rollback procedures—similar to DevOps methodologies—ensuring that data pipelines can evolve continuously without disrupting downstream systems.
With platforms like Alation, organizations can integrate metadata-driven automation into every stage of their data pipeline—reducing manual overhead, improving governance, and accelerating delivery.
Use Automated Testing and Validation for Data Quality
Just as DevOps tests code, DataOps must test data. Implement automated testing frameworks that verify schema consistency, data freshness, and referential integrity.
Platforms like Alation help automate these validations and surface data quality insights directly in the catalog, ensuring only trusted data feeds analytics and AI systems.
Using DataOps to Empower Users
At its best, DataOps isn’t just a technical methodology—it’s a cultural transformation. It connects IT and business, empowering users to explore, analyze, and act on data confidently.
By deploying tested, trusted, and monitored data solutions, DataOps breaks down silos between data consumers and producers. The result is a data culture—an environment where data is treated as a shared asset, not a departmental resource.
With Alation, organizations can accelerate this transformation by combining metadata intelligence, lineage, and collaboration tools. Together, these capabilities ensure that every stakeholder—from data engineer to executive—can work from the same trusted source of truth.
Final Thoughts
As enterprises embrace AI and data products, DataOps is becoming as foundational as DevOps was to software innovation a decade ago. The future of both lies in automation, governance, and collaboration—powered by metadata intelligence.
With the right DataOps strategy and platform, organizations can transform data chaos into clarity—delivering trusted insights faster and fueling the next generation of AI innovation.
See the difference: book a demo with us today.
- An Overview of DataOps vs. DevOps
- What Are the Differences Between DataOps and DevOps?
- What Are the Similarities Between DataOps and DevOps?
- What Are the Top Use Cases for DataOps and DevOps?
- Best Practices for DataOps Implementation
- Using DataOps to Empower Users
- Final Thoughts
Contents
FAQs
What challenges do businesses face when implementing DataOps compared to traditional DevOps?
The biggest challenges include data complexity, governance requirements, and cross-functional alignment. Unlike code, data constantly changes—introducing variability in schema, source, and quality. DataOps must manage this fluidity while ensuring compliance and collaboration across business and technical teams.
Why should businesses adopt DataOps platforms for improved data governance and compliance?
DataOps platforms like Alation provide automated lineage tracking, metadata management, and quality monitoring, ensuring that data remains compliant, auditable, and trustworthy. This is essential for meeting regulations and supporting ethical AI development.
How does the role of a DataOps engineer differ from a DevOps engineer?
A DevOps engineer focuses on software deployment pipelines, while a DataOps engineer focuses on data pipelines and lifecycle management. The latter must understand data governance, transformation logic, and business context—skills that extend beyond traditional operations.
Can businesses use DataOps to enhance data quality and self-service analytics across global teams?
Absolutely. By combining automated data validation with collaborative catalogs like Alation, organizations can maintain consistent data quality standards worldwide while empowering teams to access and trust data independently.
Tagged with
Loading...